Master Thesis
"Reinforcement Learning for Autonomous Driving: Comfort and Robustness to Noise"
Authors: Giovanni Lucente
Supervisor: Marcello Restelli
Abstract
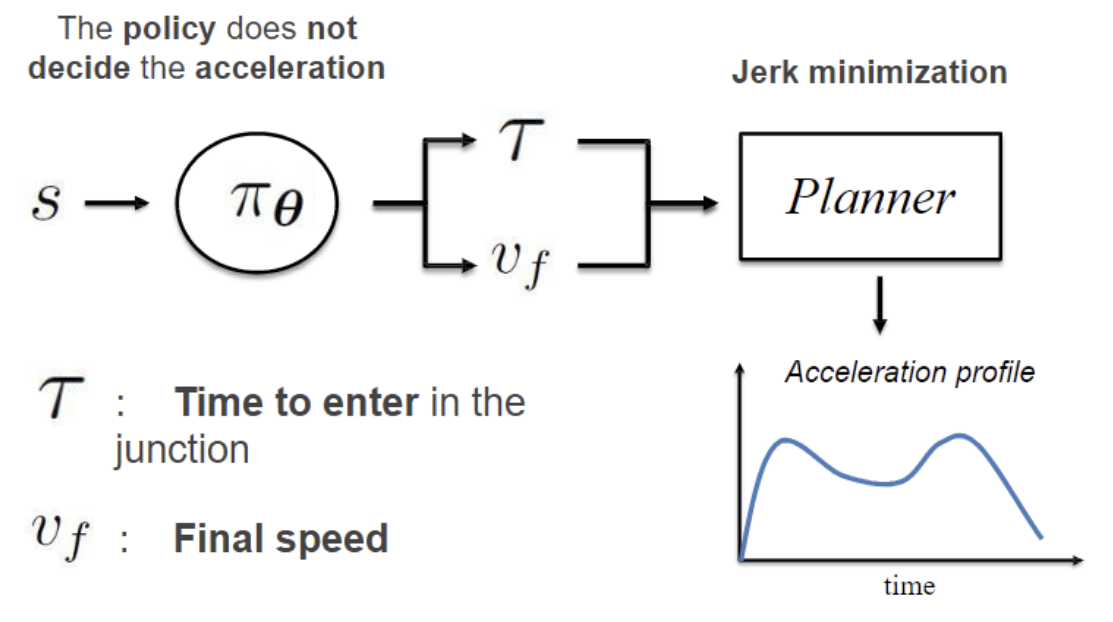
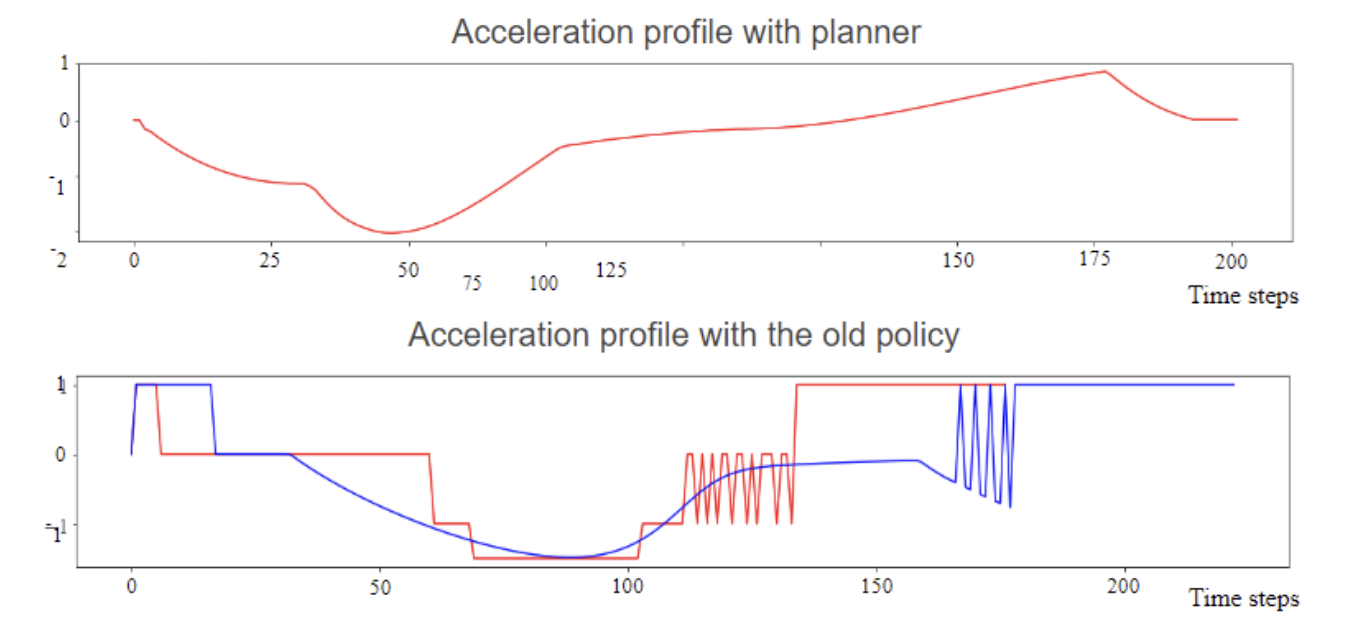
In the framework of high-level decision making for autonomous driving, Reinforcement Learning techniques have taken a central position in the development of algorithms and procedures for humanlike decisions. Past works show how effective this kind of techniques is in many research fields. Also in robotics and in particular in autonomous driving, the literature shows great results in this sense. There is now more emphasis on the second stage of development, regarding for instance the robustness to sensor noise and the driving comfort. In this project, these topics are faced, providing a deep analysis on the robustness of the algorithm to noise and proposing a new solution for the comfort issue. The first point is to test the PGPE algorithm, with a rule-based policy, i.e. the tool that models the behavior of the autonomous agent, in the SUMO simulation environment adding different models of noise. The noise is added on the state variables, taken as input of the policy, and by using ARMA processes, autocorrelation in time and cross correlation among variables is considered. The problem of comfort is faced with the proposal of a two step policy, a first step that is responsible for high level decisions, such as the time to enter in a cross, and a low level planner downstream. The planner receives as input the high level decisions and outputs the acceleration profile, optimizing the driving comfort. Some results are presented, showing that the research and development direction is promising.
Links
Full Text: Read Here
Scheme and Results